For an engineer, analyzing and improving performance of software systems are fairly common tasks. System performance is a well-researched area. We have a number of established performance analysis methods as well as a rich toolbox of techniques to use and trade-offs we can make when designing software systems. There have been numerous times when I’ve had to improve the response time of an API by optimizing an algorithm, introducing caching, tuning garbage collection, reducing queuing, or trading throughput for latency. Once I started thinking more about team and organizational performance, it became clear that there are many parallels between software systems and teams and that both can benefit from some of the same techniques. In this article, I’d like to look at a few of these similarities and explore how we can improve the performance of our teams and the software that they build.
Workstations and Queues
Let’s first take a look at what makes organizations and software similar. To begin, they both take some inputs and combine them to produce outputs, sometimes with side-effects. In organizations, division of labor and specialization leads to departments, whereas in software, similar pressures lead to the creation of modules, components, and services. Similar to the debates that engineers have around breaking up software components along the business or functional lines, organization leaders have to decide between functional, matrix, or product organizations. Furthermore, Conway’s law observes that communication paths in software mimic the communication structure of the organization that produces it.
For the purposes of performance analysis, it is most useful to look at how inputs get transformed into outputs in both cases. For organizations, such transformations can be modeled as value streams. A value stream traces an individual piece of work on its path throughout the organization. Usually, such work flows through several workstations which transform it. The project spends some time in queues, waiting on a workstation to become available, and occasionally may revisit parts of the process, if an error happens or rework is required. Eventually, the work item exits the system as a result that is valuable to the customer. The end-to-end processing time is known as lead time, and performance is analyzed using value-stream mapping.
At this point, the parallels with software should become obvious. A user request enters the system, where it gets processed by multiple services (workstations). It spends some time in queues, occasionally errors happen, exceptions need to be handled, and processing has to be retried. In the end, a response is returned back to the user. The response time is determined by the total processing time as well as time spent in queues. Staged event-driven architecture models this process explicitly and makes the parallels to value stream mapping very clear:

Source: SEDA: An Architecture for Well-Conditioned, Scalable Internet Services
While SEDA refers to a specific type of architecture with explicit queues and dynamically sized thread pools, many distributed systems implement very similar patterns in practice, even if they don’t follow it formally.
In order to get optimal performance, whether from organizations or software systems, we want work to flow smoothly through the system, with as few handoffs as possible, minimal queue time, and less time wasted on errors and rework. Let’s look at how we can achieve these goals.
Throughput vs. Latency
One of the most important trade-offs you can make when designing a system for high performance is trading throughput for latency. Throughput is the amount of work a system can do in a unit of time, whereas latency is the measure of how long the system takes to process a unit of work. Both can be used to characterize system performance, and most of the time, there is tension between the two. This applies both to software systems and organizations. Of course, all other things being equal, lower latency would mean more work being processed in a unit of time. However, such an ideal situation is uncommon because the exact measures that are used to increase system throughput also increase the amount of time it takes to accomplish an individual task. Two of these measures are batching and controlling resource utilization.
Batching
Batching is a very common technique for increasing system throughput. We batch service requests, database reads, and filesystem writes. We use frameworks such as Hadoop for batch processing large amounts of work. Java garbage collection makes a trade-off between batch algorithms that pause the application to perform garbage collection and concurrent algorithms that continuously work in the background. While the former are more efficient and result in higher throughput, individual requests can be slowed down significantly by pauses. The latter algorithms are less efficient but they often allow the application to offer consistently low latency. Similarly, in our private lives we might chose to batch process email in the morning, thus increasing our total productivity during the day at the cost of a longer response time to the email messages.
Batch processing has another unintended side-effect: higher potential for waste. Imagine if you spent a week on creating a number of reports for your manager, only to discover in the end that they are in the wrong format. Likewise, consider a service processing a large batch of requests only to discover in the end that a dependency is unavailable. In both cases we would have to re-process the whole batch. Smaller batch sizes help get fast feedback and correct defects early in the process. This is why achieving the batch size of one is such a core tenet of lean production systems that focus on minimizing waste.
Resource Utilization
One of the ways to increase the total output of a team is to ask everyone to work harder and make sure that they are busy 100% of the time. Sounds reasonable? Well, things are more complicated if people need to collaborate, for example, when there are dependencies between workstations. Due to variability in task processing rates, it is impossible to keep everyone 100% busy without introducing some level of queuing. With work accumulating in queues, individuals would need to multitask more in order to keep themselves busy while they wait on responses to their requests. Since more time is spent on context-switching and keeping track of unfinished work, their total productivity decreases, even though they are staying 100% busy. Additionally, imagine if an urgent request comes into the system. Either it would have to sit in the queues, or the existing work would need to be preempted, introducing more disruption into the system. Additionally, there is a human cost to this working style: no time left for innovation, low job satisfaction, high stress, and the perverse incentive to work slower and look busier. Tom DeMarco debunks much of the culture of busyness in Slack.
Coincidentally, this is exactly what happens in software systems under overload. Queuing theory describes the relationship between throughput and latency under an increasing load. Ideally, a system would be able to serve n requests per second, if a single request takes 1/n seconds to complete. However, neither request arrivals nor service times are completely uniform in reality. Instead, requests arrive in spikes, making servers contend for resources. When this happens, requests start getting queued and the response times increase. For the system to absorb such spikes and to allow time for queues to clear, slack capacity is required. Without this capacity, the system would operate with permanent queuing (bufferbloat) and consistently elevated response times. With higher variance in request arrival and processing times, more slack capacity is required. The point in utilization at which queuing begins to dominate response time is known as the knee:
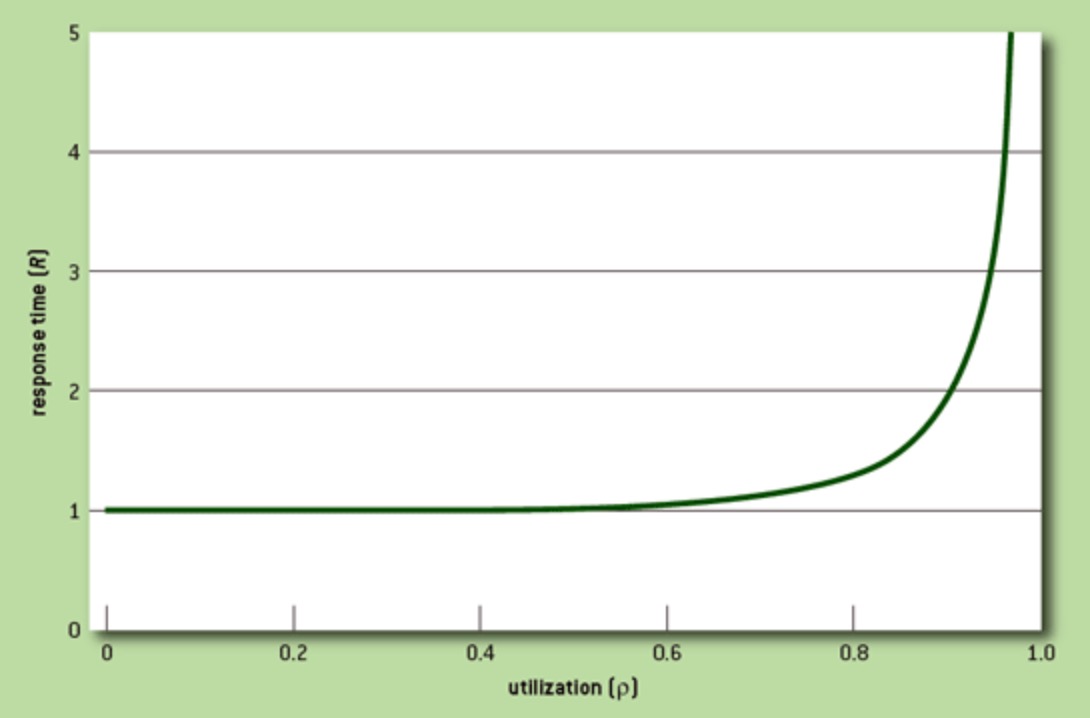
Source: Thinking Clearly about Performance
The takeaway is that organizations and software systems both achieve optimal performance at lower levels of utilization, enabling them to absorb spikes in workload, minimize queuing, and allow for more flexibility in the system.
Universal Scalability Law
Scalability refers to the ability of the system to handle a growing amount of work by adding resources to it. In the ideal case of linear scalability, adding resources to the system increases its throughput proportionately. However, most systems scale sub-linearly because they cannot fully take advantage of the added capacity. There are several reasons for this. Since not all work is perfectly parallelizable, improvements in performance are limited to the parts that can be parallelized. The part that cannot be parallelized requires coordination and agreement between the parties involved, which introduces communication overhead. More formally, we speak of contention for shared resources and the coherence delay of communication. The relationship between these variables and scalability is known as the Universal Scalability Law, which is commonly used for quantifying the scalability of software systems.
Universal Scalability Law applies to organizations as well. Adrian Colyer covered this in depth in ”Applying the Universal Scalability Law to organisations,” so I will only summarize the key points. We can reduce contention in the organization by delegating as much of the decision-making down the management chain as possible so that individuals performing the tasks are empowered to work efficiently with a minimum number of sign-offs and approvals. This is also known as the principle of subsidiarity, and it helps not only prevent managers from becoming bottlenecks in the organization, but improves the quality of decisions. Reducing the cost of coherence requires keeping the number of people involved in each decision to a minimum in order to reduce communication overhead.
Minimizing Handoffs
Every time there is a handoff between services, we need to serialize a request, send it over the network, deserialize it, validate it, enqueue it for processing, etc. Additionally, we need to deal with errors, timeouts, and retries. This is why we try to avoid such chatty communication by designing services around domain boundaries with coarse-grained APIs, a high degree of autonomy, strong cohesion within, and loose coupling to outside systems. These techniques help us build resilient and scalable distributed systems.
The exact same logic applies to organizations: “each time the work passes from team to team, we require all sorts of communication: requesting, specifying, signaling, coordinating, and often prioritizing, scheduling, deconflicting, testing, and verifying.” Each handoff creates a potential for errors, misunderstanding, queuing, and loss of context. For this reason, both the quality and the end-to-end latency of work can be improved significantly by reducing handoffs. This can be done by adjusting team boundaries (similar to what we do when designing services), automation, or eliminating work that doesn’t add value.
Sync vs. Async Communication
In software, asynchronous communication has numerous benefits over synchronous communication. It enables temporal decoupling between components, helps isolate failure, enables pub-sub communication topology, helps withstand spikes in load, and enables simple retries and batching. This is in contrast to synchronous communication, which is mostly point-to-point, requires both parties to be available at the same time, and often contends for time with other potentially more urgent work.
Continuing with a software analogy, a meeting requires each participant to be synchronously available at the same time at the cost of mutual exclusion of all other activities. While it might be necessary if strong consistency through consensus is required, the cost of attending a meeting is high, and the time it takes to acquire locks on everyone’s calendars is long. Therefore, in organizations, similar to software systems, asynchronous communication usually will result in higher throughput and lower latency.
Conclusion
As we can see, there are a surprising number of similarities between software systems and teams that build them. In many cases, performance analysis and optimization techniques from one domain can be directly applied to the other. While this article covers some of the high-level performance characteristics, there are many more analogies between the two fields. For example, consider the performance of using shared or separate queues for request processing and its implications for the structure of team backlogs. Have you come across other examples? Please share them in the comment section.